22 Managing Storage Pools #
Ceph stores data within pools. Pools are logical groups for storing objects. When you first deploy a cluster without creating a pool, Ceph uses the default pools for storing data. The following important highlights relate to Ceph pools:
Resilience: You can set how many OSDs, buckets, or leaves are allowed to fail without losing data. For replicated pools, it is the desired number of copies/replicas of an object. New pools are created with a default count of replicas set to 3. For erasure coded pools, it is the number of coding chunks (that is m=2 in the erasure code profile).
Placement Groups: are internal data structures for storing data in a pool across OSDs. The way Ceph stores data into PGs is defined in a CRUSH Map. You can set the number of placement groups for a pool at its creation. A typical configuration uses approximately 100 placement groups per OSD to provide optimal balancing without using up too many computing resources. When setting up multiple pools, be careful to ensure you set a reasonable number of placement groups for both the pool and the cluster as a whole.
CRUSH Rules: When you store data in a pool, objects and its replicas (or chunks in case of erasure coded pools) are placed according to the CRUSH ruleset mapped to the pool. You can create a custom CRUSH rule for your pool.
Snapshots: When you create snapshots with
ceph osd pool mksnap, you effectively take a snapshot of a particular pool.
To organize data into pools, you can list, create, and remove pools. You can also view the usage statistics for each pool.
22.1 Associate Pools with an Application #
Before using pools, you need to associate them with an application. Pools that will be used with CephFS, or pools that are automatically created by Object Gateway are automatically associated.
For other cases, you can manually associate a free-form application name with a pool:
cephadm@adm > ceph osd pool application enable pool_name application_nameTip: Default Application Names
CephFS uses the application name cephfs, RADOS Block Device uses
rbd, and Object Gateway uses rgw.
A pool can be associated with multiple applications, and each application can have its own metadata. You can display the application metadata for a given pool using the following command:
cephadm@adm > ceph osd pool application get pool_name22.2 Operating Pools #
This section introduces practical information to perform basic tasks with pools. You can find out how to list, create, and delete pools, as well as show pool statistics or manage snapshots of a pool.
22.2.1 List Pools #
To list your cluster’s pools, execute:
cephadm@adm > ceph osd pool ls22.2.2 Create a Pool #
A pool can be created as either 'replicated' to recover from lost OSDs by keeping multiple copies of the objects or 'erasure' to get a kind of generalized RAID5/6 capability. Replicated pools require more raw storage, while erasure coded pools require less raw storage. Default is 'replicated'.
To create a replicated pool, execute:
cephadm@adm > ceph osd pool create pool_name pg_num pgp_num replicated crush_ruleset_name \
expected_num_objectsTo create an erasure coded pool, execute:
cephadm@adm > ceph osd pool create pool_name pg_num pgp_num erasure erasure_code_profile \
crush_ruleset_name expected_num_objects
The ceph osd pool create can fail if you exceed the
limit of placement groups per OSD. The limit is set with the option
mon_max_pg_per_osd.
- pool_name
The name of the pool. It must be unique. This option is required.
- pg_num
The total number of placement groups for the pool. This option is required. Default value is 8.
- pgp_num
The total number of placement groups for placement purposes. This should be equal to the total number of placement groups, except for placement group splitting scenarios. This option is required. Default value is 8.
- crush_ruleset_name
The name of the crush ruleset for this pool. If the specified ruleset does not exist, the creation of replicated pools will fail with -ENOENT. For replicated pools it is the ruleset specified by the
osd pool default crush replicated rulesetconfiguration variable. This ruleset must exist. For erasure pools it is 'erasure-code' if the default erasure code profile is used or POOL_NAME otherwise. This ruleset will be created implicitly if it does not exist already.- erasure_code_profile=profile
For erasure coded pools only. Use the erasure code profile. It must be an existing profile as defined by
osd erasure-code-profile set.When you create a pool, set the number of placement groups to a reasonable value. Consider the total number of placement groups per OSD too. Placement groups are computationally expensive, so performance will degrade when you have many pools with many placement groups (for example 50 pools with 100 placement groups each).
See Section 20.4, “Placement Groups” for details on calculating an appropriate number of placement groups for your pool.
- expected_num_objects
The expected number of objects for this pool. By setting this value (together with a negative
filestore merge threshold), the PG folder splitting happens at the pool creation time. This avoids the latency impact with a runtime folder splitting.
22.2.3 Set Pool Quotas #
You can set pool quotas for the maximum number of bytes and/or the maximum number of objects per pool.
cephadm@adm > ceph osd pool set-quota pool-name max_objects obj-count max_bytes bytesFor example:
cephadm@adm > ceph osd pool set-quota data max_objects 10000To remove a quota, set its value to 0.
22.2.4 Delete a Pool #
Warning: Pool Deletion is Not Reversible
Pools may contain important data. Deleting a pool causes all data in the pool to disappear, and there is no way to recover it.
Because inadvertent pool deletion is a real danger, Ceph implements two mechanisms that prevent pools from being deleted. Both mechanisms must be disabled before a pool can be deleted.
The first mechanism is the NODELETE flag. Each pool has
this flag, and its default value is 'false'. To find out the value of this
flag on a pool, run the following command:
cephadm@adm > ceph osd pool get pool_name nodelete
If it outputs nodelete: true, it is not possible to
delete the pool until you change the flag using the following command:
cephadm@adm > ceph osd pool set pool_name nodelete false
The second mechanism is the cluster-wide configuration parameter
mon allow pool delete, which defaults to 'false'. This
means that, by default, it is not possible to delete a pool. The error
message displayed is:
Error EPERM: pool deletion is disabled; you must first set the mon_allow_pool_delete config option to true before you can destroy a pool
To delete the pool in spite of this safety setting, you can temporarily set
mon allow pool delete to 'true', delete the pool, and then
return the parameter to 'false':
cephadm@adm >ceph tell mon.* injectargs --mon-allow-pool-delete=truecephadm@adm >ceph osd pool delete pool_name pool_name --yes-i-really-really-mean-itcephadm@adm >ceph tell mon.* injectargs --mon-allow-pool-delete=false
The injectargs command displays the following message:
injectargs:mon_allow_pool_delete = 'true' (not observed, change may require restart)
This is merely confirming that the command was executed successfully. It is not an error.
If you created your own rulesets and rules for a pool you created, you should consider removing them when you no longer need your pool.
22.2.5 Rename a Pool #
To rename a pool, execute:
cephadm@adm > ceph osd pool rename current-pool-name new-pool-nameIf you rename a pool and you have per-pool capabilities for an authenticated user, you must update the user’s capabilities with the new pool name.
22.2.6 Show Pool Statistics #
To show a pool’s usage statistics, execute:
cephadm@adm > rados df
POOL_NAME USED OBJECTS CLONES COPIES MISSING_ON_PRIMARY UNFOUND DEGRADED RD_OPS RD WR_OPS WR USED COMPR UNDER COMPR
.rgw.root 768 KiB 4 0 12 0 0 0 44 44 KiB 4 4 KiB 0 B 0 B
cephfs_data 960 KiB 5 0 15 0 0 0 5502 2.1 MiB 14 11 KiB 0 B 0 B
cephfs_metadata 1.5 MiB 22 0 66 0 0 0 26 78 KiB 176 147 KiB 0 B 0 B
default.rgw.buckets.index 0 B 1 0 3 0 0 0 4 4 KiB 1 0 B 0 B 0 B
default.rgw.control 0 B 8 0 24 0 0 0 0 0 B 0 0 B 0 B 0 B
default.rgw.log 0 B 207 0 621 0 0 0 5372132 5.1 GiB 3579618 0 B 0 B 0 B
default.rgw.meta 961 KiB 6 0 18 0 0 0 155 140 KiB 14 7 KiB 0 B 0 B
example_rbd_pool 2.1 MiB 18 0 54 0 0 0 3350841 2.7 GiB 118 98 KiB 0 B 0 B
iscsi-images 769 KiB 8 0 24 0 0 0 1559261 1.3 GiB 61 42 KiB 0 B 0 B
mirrored-pool 1.1 MiB 10 0 30 0 0 0 475724 395 MiB 54 48 KiB 0 B 0 B
pool2 0 B 0 0 0 0 0 0 0 0 B 0 0 B 0 B 0 B
pool3 333 MiB 37 0 111 0 0 0 3169308 2.5 GiB 14847 118 MiB 0 B 0 B
pool4 1.1 MiB 13 0 39 0 0 0 1379568 1.1 GiB 16840 16 MiB 0 B 0 BA description of individual columns follow:
- USED
Number of bytes used by the pool.
- OBJECTS
Number of objects stored in the pool.
- CLONES
Number of clones stored in the pool. When a snapshot is created and one writes to an object, instead of modifying the original object its clone is created so the original snapshotted object content is not modified.
- COPIES
Number of object replicas. For example, if a replicated pool with the replication factor 3 has 'x' objects, it will normally have 3 * x copies.
- MISSING_ON_PRIMARY
Number of objects in the degraded state (not all copies exist) while the copy is missing on the primary OSD.
- UNFOUND
Number of unfound objects.
- DEGRADED
Number of degraded objects.
- RD_OPS
Total number of read operations requested for this pool.
- RD
Total number of bytes read from this pool.
- WR_OPS
Total number of write operations requested for this pool.
- WR
Total number of bytes written to the pool. Note that it is not the same as the pool's usage because you can write to the same object many times. The result is that the pool's usage will remain the same but the number of bytes written to the pool will grow.
- USED COMPR
Number of bytes allocated for compressed data.
- UNDER COMPR
Number of bytes that the compressed data occupy when it is not compressed.
22.2.7 Get Pool Values #
To get a value from a pool, execute:
cephadm@adm > ceph osd pool get pool-name keyYou can get values for keys listed in Section 22.2.8, “Set Pool Values” plus the following keys:
- pg_num
The number of placement groups for the pool.
- pgp_num
The effective number of placement groups to use when calculating data placement. Valid range is equal to or less than
pg_num.
Tip: All of a Pool's Values
To list all values related to a specific pool, run:
cephadm@adm > ceph osd pool get POOL_NAME all22.2.8 Set Pool Values #
To set a value to a pool, execute:
cephadm@adm > ceph osd pool set pool-name KEY VALUEThe following is a list of pool values sorted by a pool type:
Common Pool Values #
- crash_replay_interval
The number of seconds to allow clients to replay acknowledged, but uncommitted requests.
- pg_num
The number of placement groups for the pool. If you add new OSDs to the cluster, verify the value for placement groups on all pools targeted for the new OSDs.
- pgp_num
The effective number of placement groups to use when calculating data placement.
- crush_ruleset
The ruleset to use for mapping object placement in the cluster.
- hashpspool
Set (1) or unset (0) the HASHPSPOOL flag on a given pool. Enabling this flag changes the algorithm to better distribute PGs to OSDs. After enabling this flag on a pool whose HASHPSPOOL flag was set to the default 0, the cluster starts backfilling to have a correct placement of all PGs again. Be aware that this can create quite substantial I/O load on a cluster, therefore do not enable the flag from 0 to 1 on highly loaded production clusters.
- nodelete
Prevents the pool from being removed.
- nopgchange
Prevents the pool's
pg_numandpgp_numfrom being changed.- noscrub,nodeep-scrub
Disables (deep) scrubbing of the data for the specific pool to resolve temporary high I/O load.
- write_fadvise_dontneed
Set or unset the
WRITE_FADVISE_DONTNEEDflag on a given pool's read/write requests to bypass putting data into cache. Default isfalse. Applies to both replicated and EC pools.- scrub_min_interval
The minimum interval in seconds for pool scrubbing when the cluster load is low. The default
0means that theosd_scrub_min_intervalvalue from the Ceph configuration file is used.- scrub_max_interval
The maximum interval in seconds for pool scrubbing, regardless of the cluster load. The default
0means that theosd_scrub_max_intervalvalue from the Ceph configuration file is used.- deep_scrub_interval
The interval in seconds for the pool deep scrubbing. The default
0means that theosd_deep_scrubvalue from the Ceph configuration file is used.
Replicated Pool Values #
- size
Sets the number of replicas for objects in the pool. See Section 22.2.9, “Set the Number of Object Replicas” for further details. Replicated pools only.
- min_size
Sets the minimum number of replicas required for I/O. See Section 22.2.9, “Set the Number of Object Replicas” for further details. Replicated pools only.
- nosizechange
Prevents the pool's size from being changed. When a pool is created, the default value is taken from the value of the
osd_pool_default_flag_nosizechangeparameter which isfalseby default. Applies to replicated pools only because you cannot change size for EC pools.- hit_set_type
Enables hit set tracking for cache pools. See Bloom Filter for additional information. This option can have the following values:
bloom,explicit_hash,explicit_object. Default isbloom, other values are for testing only.- hit_set_count
The number of hit sets to store for cache pools. The higher the number, the more RAM consumed by the
ceph-osddaemon. Default is0.- hit_set_period
The duration of a hit set period in seconds for cache pools. The higher the number, the more RAM consumed by the
ceph-osddaemon. When a pool is created, the default value is taken from the value of theosd_tier_default_cache_hit_set_periodparameter, which is1200by default. Applies to replicated pools only because EC pools cannot be used as a cache tier.- hit_set_fpp
The false positive probability for the bloom hit set type. See Bloom Filter for additional information. Valid range is 0.0 - 1.0 Default is
0.05- use_gmt_hitset
Force OSDs to use GMT (Greenwich Mean Time) time stamps when creating a hit set for cache tiering. This ensures that nodes in different time zones return the same result. Default is
1. This value should not be changed.- cache_target_dirty_ratio
The percentage of the cache pool containing modified (dirty) objects before the cache tiering agent will flush them to the backing storage pool. Default is
0.4.- cache_target_dirty_high_ratio
The percentage of the cache pool containing modified (dirty) objects before the cache tiering agent will flush them to the backing storage pool with a higher speed. Default is
0.6.- cache_target_full_ratio
The percentage of the cache pool containing unmodified (clean) objects before the cache tiering agent will evict them from the cache pool. Default is
0.8.- target_max_bytes
Ceph will begin flushing or evicting objects when the
max_bytesthreshold is triggered.- target_max_objects
Ceph will begin flushing or evicting objects when the
max_objectsthreshold is triggered.- hit_set_grade_decay_rate
Temperature decay rate between two successive
hit_sets. Default is20.- hit_set_search_last_n
Count at most
Nappearances inhit_sets for temperature calculation. Default is1.- cache_min_flush_age
The time (in seconds) before the cache tiering agent will flush an object from the cache pool to the storage pool.
- cache_min_evict_age
The time (in seconds) before the cache tiering agent will evict an object from the cache pool.
Erasure Coded Pool Values #
- fast_read
If this flag is enabled on erasure coding pools, then the read request issues sub-reads to all shards, and waits until it receives enough shards to decode to serve the client. In the case of jerasure and isa erasure plug-ins, when the first
Kreplies return, then the client’s request is served immediately using the data decoded from these replies. This approach causes more CPU load and less disk/network load. Currently, this flag is only supported for erasure coding pools. Default is0.
22.2.9 Set the Number of Object Replicas #
To set the number of object replicas on a replicated pool, execute the following:
cephadm@adm > ceph osd pool set poolname size num-replicasThe num-replicas includes the object itself. For example if you want the object and two copies of the object for a total of three instances of the object, specify 3.
Warning: Do Not Set Less Than 3 Replicas
If you set the num-replicas to 2, there will be only one copy of your data. If you lose one object instance, you need to trust that the other copy has not been corrupted, for example since the last scrubbing during recovery (refer to Section 20.6, “Scrubbing” for details).
Setting a pool to one replica means that there is exactly one instance of the data object in the pool. If the OSD fails, you lose the data. A possible usage for a pool with one replica is storing temporary data for a short time.
Tip: Setting More Than 3 Replicas
Setting 4 replicas for a pool increases the reliability by 25%.
In case of two data centers, you need to set at least 4 replicas for a pool to have two copies in each data center so that if one data center is lost, two copies still exist and you can still lose one disk without losing data.
Note
An object might accept I/Os in degraded mode with fewer than pool
size replicas. To set a minimum number of required replicas for
I/O, you should use the min_size setting. For example:
cephadm@adm > ceph osd pool set data min_size 2
This ensures that no object in the data pool will receive I/O with fewer
than min_size replicas.
Tip: Get the Number of Object Replicas
To get the number of object replicas, execute the following:
cephadm@adm > ceph osd dump | grep 'replicated size'
Ceph will list the pools, with the replicated size
attribute highlighted. By default, Ceph creates two replicas of an
object (a total of three copies, or a size of 3).
22.3 Pool Migration #
When creating a pool (see Section 22.2.2, “Create a Pool”) you need to specify its initial parameters, such as the pool type or the number of placement groups. If you later decide to change any of these parameters—for example when converting a replicated pool into an erasure coded one, or decreasing the number of placement groups—you need to migrate the pool data to another one whose parameters suit your deployment.
This section describes two migration methods—a cache
tier method for general pool data migration, and a method using
rbd migrate sub-commands to migrate RBD images to a new
pool. Each method has its specifics and limitations.
22.3.1 Limitations #
You can use the cache tier method to migrate from a replicated pool to either an EC pool or another replicated pool. Migrating from an EC pool is not supported.
You cannot migrate RBD images and CephFS exports from a replicated pool to an EC pool. The reason is that EC pools do not support
omap, while RBD and CephFS useomapto store its metadata. For example, the header object of the RBD will fail to be flushed. But you can migrate data to EC pool, leaving metadata in replicated pool.The
rbd migrationmethod allows migrating images with minimal client downtime. You only need to stop the client before thepreparestep and start it afterward. Note that only alibrbdclient that supports this feature (Ceph Nautilus or newer) will be able to open the image just after thepreparestep, while olderlibrbdclients or thekrbdclients will not be able to open the image until thecommitstep is executed.
22.3.2 Migrate Using Cache Tier #
The principle is simple—include the pool that you need to migrate into a cache tier in reverse order. Find more details on cache tiers in Book “Tuning Guide”, Chapter 7 “Cache Tiering”. The following example migrates a replicated pool named 'testpool' to an erasure coded pool:
Procedure 22.1: Migrating Replicated to Erasure Coded Pool #
Create a new erasure coded pool named 'newpool'. Refer to Section 22.2.2, “Create a Pool” for a detailed explanation of pool creation parameters.
cephadm@adm >ceph osd pool create newpool PG_NUM PGP_NUM erasure defaultVerify that the used client keyring provides at least the same capabilities for 'newpool' as it does for 'testpool'.
Now you have two pools: the original replicated 'testpool' filled with data, and the new empty erasure coded 'newpool':
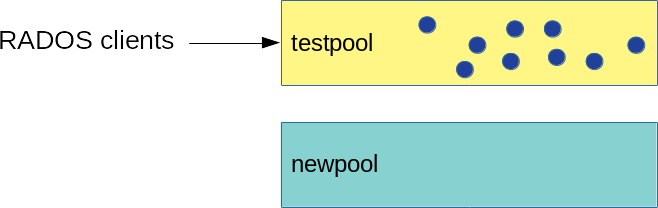
Figure 22.1: Pools before Migration #
Set up the cache tier and configure the replicated pool 'testpool' as a cache pool. The
-force-nonemptyoption allows adding a cache tier even if the pool already has data:cephadm@adm >ceph tell mon.* injectargs \ '--mon_debug_unsafe_allow_tier_with_nonempty_snaps=1'cephadm@adm >ceph osd tier add newpool testpool --force-nonemptycephadm@adm >ceph osd tier cache-mode testpool proxy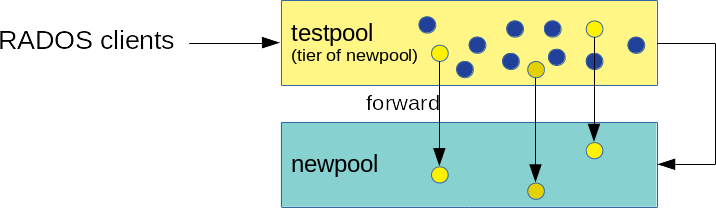
Figure 22.2: Cache Tier Setup #
Force the cache pool to move all objects to the new pool:
cephadm@adm >rados -p testpool cache-flush-evict-all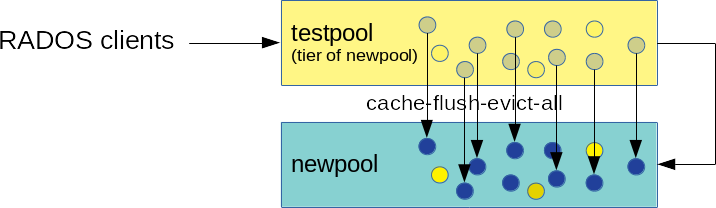
Figure 22.3: Data Flushing #
Until all the data has been flushed to the new erasure coded pool, you need to specify an overlay so that objects are searched on the old pool:
cephadm@adm >ceph osd tier set-overlay newpool testpoolWith the overlay, all operations are forwarded to the old replicated 'testpool':
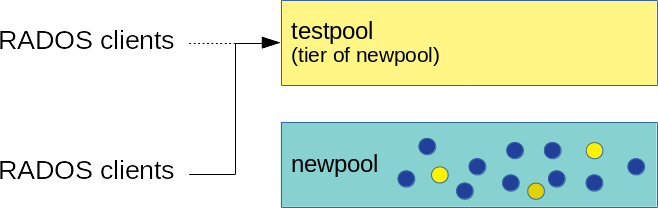
Figure 22.4: Setting Overlay #
Now you can switch all the clients to access objects on the new pool.
After all data is migrated to the erasure coded 'newpool', remove the overlay and the old cache pool 'testpool':
cephadm@adm >ceph osd tier remove-overlay newpoolcephadm@adm >ceph osd tier remove newpool testpool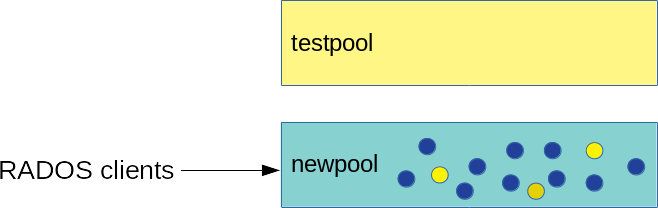
Figure 22.5: Migration Complete #
Run
cephadm@adm >ceph tell mon.* injectargs \ '--mon_debug_unsafe_allow_tier_with_nonempty_snaps=0'
22.3.3 Migrating RBD Images #
The following is the recommended way to migrate RBD images from one replicated pool to another replicated pool.
Stop clients (such as a virtual machine) from accessing the RBD image.
Create a new image in the target pool, with the parent set to the source image:
cephadm@adm >rbd migration prepare SRC_POOL/IMAGE TARGET_POOL/IMAGE
Tip: Migrate Only Data to an EC Pool
If you need to migrate only the image data to a new EC pool and leave the metadata in the original replicated pool, run the following command instead:
cephadm@adm >rbd migration prepare SRC_METADATA_POOL/IMAGE TARGET_METADATA_POOL/IMAGE \ --data-pool TARGET_DATA_POOL/IMAGELet clients access the image in the target pool.
Migrate data to the target pool:
cephadm@adm >rbd migration execute SRC_POOL/IMAGERemove the old image:
cephadm@adm >rbd migration commit SRC_POOL/IMAGE
22.4 Pool Snapshots #
Pool snapshots are snapshots of the state of the whole Ceph pool. With pool snapshots, you can retain the history of the pool's state. Creating pool snapshots consumes storage space proportional to the pool size. Always check the related storage for enough disk space before creating a snapshot of a pool.
22.4.1 Make a Snapshot of a Pool #
To make a snapshot of a pool, run:
cephadm@adm > ceph osd pool mksnap POOL-NAME SNAP-NAMEFor example:
cephadm@adm > ceph osd pool mksnap pool1 snap1
created pool pool1 snap snap122.4.2 List Snapshots of a Pool #
To list existing snapshots of a pool, run:
cephadm@adm > rados lssnap -p POOL_NAMEFor example:
cephadm@adm > rados lssnap -p pool1
1 snap1 2018.12.13 09:36:20
2 snap2 2018.12.13 09:46:03
2 snaps22.4.3 Remove a Snapshot of a Pool #
To remove a snapshot of a pool, run:
cephadm@adm > ceph osd pool rmsnap POOL-NAME SNAP-NAME22.5 Data Compression #
BlueStore (find more details in Book “Deployment Guide”, Chapter 1 “SUSE Enterprise Storage 6 and Ceph”, Section 1.4 “BlueStore”) provides on-the-fly data compression to save disk space. The compression ratio depends on the data stored in the system. Note that compression/decompression requires additional CPU power.
You can configure data compression globally (see Section 22.5.3, “Global Compression Options”) and then override specific compression settings for each individual pool.
You can enable or disable pool data compression, or change the compression algorithm and mode at any time, regardless of whether the pool contains data or not.
No compression will be applied to existing data after enabling the pool compression.
After disabling the compression of a pool, all its data will be decompressed.
22.5.1 Enable Compression #
To enable data compression for a pool named POOL_NAME, run the following command:
cephadm@adm >cephosd pool set POOL_NAME compression_algorithm COMPRESSION_ALGORITHMcephadm@adm >cephosd pool set POOL_NAME compression_mode COMPRESSION_MODE
Tip: Disabling Pool Compression
To disable data compression for a pool, use 'none' as the compression algorithm:
cephadm@adm >cephosd pool set POOL_NAME compression_algorithm none
22.5.2 Pool Compression Options #
A full list of compression settings:
- compression_algorithm
Possible values are
none,zstd,snappy. Default issnappy.Which compression algorithm to use depends on the specific use case. Several recommendations follow:
Use the default
snappyas long as you do not have a good reason to change it.zstdoffers a good compression ratio, but causes high CPU overhead when compressing small amounts of data.Run a benchmark of these algorithms on a sample of your actual data while keeping an eye on the CPU and memory usage of your cluster.
- compression_mode
Possible values are
none,aggressive,passive,force. Default isnone.none: compress neverpassive: compress if hintedCOMPRESSIBLEaggressive: compress unless hintedINCOMPRESSIBLEforce: compress always
- compression_required_ratio
Value: Double, Ratio = SIZE_COMPRESSED / SIZE_ORIGINAL. Default is
0.875, which means that if the compression does not reduce the occupied space by at least 12.5%, the object will not be compressed.Objects above this ratio will not be stored compressed because of the low net gain.
- compression_max_blob_size
Value: Unsigned Integer, size in bytes. Default:
0Maximum size of objects that are compressed.
- compression_min_blob_size
Value: Unsigned Integer, size in bytes. Default:
0Minimum size of objects that are compressed.
22.5.3 Global Compression Options #
The following configuration options can be set in the Ceph configuration and apply to all OSDs and not only a single pool. The pool specific configuration listed in Section 22.5.2, “Pool Compression Options” takes precedence.
- bluestore_compression_algorithm
- bluestore_compression_mode
See compression_mode
- bluestore_compression_required_ratio
- bluestore_compression_min_blob_size
Value: Unsigned Integer, size in bytes. Default:
0Minimum size of objects that are compressed. The setting is ignored by default in favor of
bluestore_compression_min_blob_size_hddandbluestore_compression_min_blob_size_ssd. It takes precedence when set to a non-zero value.- bluestore_compression_max_blob_size
Value: Unsigned Integer, size in bytes. Default:
0Maximum size of objects that are compressed before they will be split into smaller chunks. The setting is ignored by default in favor of
bluestore_compression_max_blob_size_hddandbluestore_compression_max_blob_size_ssd. It takes precedence when set to a non-zero value.- bluestore_compression_min_blob_size_ssd
Value: Unsigned Integer, size in bytes. Default:
8KMinimum size of objects that are compressed and stored on solid-state drive.
- bluestore_compression_max_blob_size_ssd
Value: Unsigned Integer, size in bytes. Default:
64KMaximum size of objects that are compressed and stored on solid-state drive before they will be split into smaller chunks.
- bluestore_compression_min_blob_size_hdd
Value: Unsigned Integer, size in bytes. Default:
128KMinimum size of objects that are compressed and stored on hard disks.
- bluestore_compression_max_blob_size_hdd
Value: Unsigned Integer, size in bytes. Default:
512KMaximum size of objects that are compressed and stored on hard disks before they will be split into smaller chunks.