7 Cache Tiering #
A cache tier is an additional storage layer implemented between the client and the standard storage. It is designed to speed up access to pools stored on slow hard disks and erasure coded pools.
Typically, cache tiering involves creating a pool of relatively fast storage devices (for example, SSD drives) configured to act as a cache tier, and a backing pool of slower and cheaper devices configured to act as a storage tier. The size of the cache pool is usually 10-20% of the storage pool.
7.1 Tiered Storage Terminology #
Cache tiering recognizes two types of pools: a cache pool and a storage pool.
Tip
For general information on pools, see Book “Administration Guide”, Chapter 22 “Managing Storage Pools”.
- storage pool
Either a standard replicated pool that stores several copies of an object in the Ceph storage cluster, or an erasure coded pool (see Book “Administration Guide”, Chapter 24 “Erasure Coded Pools”).
The storage pool is sometimes referred to as 'backing' or 'cold' storage.
- cache pool
A standard replicated pool stored on a relatively small but fast storage device with their own ruleset in a CRUSH Map.
The cache pool is also referred to as 'hot' storage.
7.2 Points to Consider #
Cache tiering may degrade the cluster performance for specific workloads. The following points show some of its aspects that you need to consider:
Workload-dependent: Whether a cache will improve performance is dependent on the workload. Because there is a cost associated with moving objects into or out of the cache, it can be more effective when most of the requests touch a small number of objects. The cache pool should be large enough to capture the working set for your workload to avoid thrashing.
Difficult to benchmark: Most performance benchmarks may show low performance with cache tiering. The reason is that they request a big set of objects, and it takes a long time for the cache to 'warm up'.
Possibly low performance: For workloads that are not suitable for cache tiering, performance is often slower than a normal replicated pool without cache tiering enabled.
libradosobject enumeration: If your application is usinglibradosdirectly and relies on object enumeration, cache tiering may not work as expected. (This is not a problem for Object Gateway, RBD, or CephFS.)
7.3 When to Use Cache Tiering #
Consider using cache tiering in the following cases:
Your erasure coded pools are stored on FileStore and you need to access them via RADOS Block Device. For more information on RBD, see Book “Administration Guide”, Chapter 23 “RADOS Block Device”.
Your erasure coded pools are stored on FileStore and you need to access them via iSCSI. For more information on iSCSI, refer to Book “Administration Guide”, Chapter 27 “Ceph iSCSI Gateway”.
You have a limited number of high-performance storage and a large collection of low-performance storage, and need to access the stored data faster.
7.4 Cache Modes #
The cache tiering agent handles the migration of data between the cache tier and the backing storage tier. Administrators have the ability to configure how this migration takes place. There are two main scenarios:
- write-back mode
In write-back mode, Ceph clients write data to the cache tier and receive an ACK from the cache tier. In time, the data written to the cache tier migrates to the storage tier and gets flushed from the cache tier. Conceptually, the cache tier is overlaid 'in front' of the backing storage tier. When a Ceph client needs data that resides in the storage tier, the cache tiering agent migrates the data to the cache tier on read, then it is sent to the Ceph client. Thereafter, the Ceph client can perform I/O using the cache tier, until the data becomes inactive. This is ideal for mutable, data such as photo or video editing, or transactional data.
- read-only mode
In read-only mode, Ceph clients write data directly to the backing tier. On read, Ceph copies the requested objects from the backing tier to the cache tier. Stale objects get removed from the cache tier based on the defined policy. This approach is ideal for immutable data such as presenting pictures or videos on a social network, DNA data, or X-ray imaging, because reading data from a cache pool that might contain out-of-date data provides weak consistency. Do not use read-only mode for mutable data.
7.5 Erasure Coded Pool and Cache Tiering #
Erasure coded pools require more resources than replicated pools. To overcome these limitations, we recommend to set a cache tier before the erasure coded pool. This is a requirement when using FileStore.
For example, if the “hot-storage” pool is made of fast storage, the “ecpool” created in Book “Administration Guide”, Chapter 24 “Erasure Coded Pools”, Section 24.3 “Erasure Code Profiles” can be speeded up with:
cephadm@adm >ceph osd tier add ecpool hot-storagecephadm@adm >ceph osd tier cache-mode hot-storage writebackcephadm@adm >ceph osd tier set-overlay ecpool hot-storage
This will place the “hot-storage” pool as a tier of ecpool in write-back mode so that every write and read to the ecpool is actually using the hot storage and benefits from its flexibility and speed.
cephadm@adm > rbd --pool ecpool create --size 10 myvolumeFor more information about cache tiering, see Chapter 7, Cache Tiering.
7.6 Setting Up an Example Tiered Storage #
This section illustrates how to set up a fast SSD cache tier (hot storage) in front of a standard hard disk (cold storage).
Tip
The following example is for illustration purposes only and includes a setup with one root and one rule for the SSD part residing on a single Ceph node.
In the production environment, cluster setups typically include more root and rule entries for the hot storage, and also mixed nodes, with both SSDs and SATA disks.
Create two additional CRUSH rules, 'replicated_ssd' for the fast SSD caching device class and 'replicated_hdd' for the slower HDD device class:
cephadm@adm >ceph osd crush rule create-replicated replicated_ssd default host ssdcephadm@adm >ceph osd crush rule create-replicated replicated_hdd default host hddSwitch all existing pools to the 'replicated_hdd' rule. This prevents Ceph from storing data to the newly added SSD devices:
cephadm@adm >ceph osd pool set POOL_NAME crush_rule replicated_hddTurn the machine into a Ceph node using
ceph-salt. Install the software and configure the host machine as described in Book “Administration Guide”, Chapter 2 “Salt Cluster Administration”, Section 2.1 “Adding New Cluster Nodes”. Let us assume that its name is node-4. This node needs to have 4 OSD disks.[...] host node-4 { id -5 # do not change unnecessarily # weight 0.012 alg straw hash 0 # rjenkins1 item osd.6 weight 0.003 item osd.7 weight 0.003 item osd.8 weight 0.003 item osd.9 weight 0.003 } [...]Edit the CRUSH map for the hot storage pool mapped to the OSDs backed by the fast SSD drives. Define a second hierarchy with a root node for the SSDs (as 'root ssd'). Additionally, change the weight and add a CRUSH rule for the SSDs. For more information on CRUSH Map, see Book “Administration Guide”, Chapter 20 “Stored Data Management”, Section 20.5 “CRUSH Map Manipulation”.
Edit the CRUSH Map directly with command line tools such as
getcrushmapandcrushtool:cephadm@adm >ceph osd crush rm-device-class osd.6 osd.7 osd.8 osd.9cephadm@adm >ceph osd crush set-device-class ssd osd.6 osd.7 osd.8 osd.9Create the hot storage pool to be used for cache tiering. Use the new 'ssd' rule for it:
cephadm@adm >ceph osd pool create hot-storage 100 100 replicated ssdCreate the cold storage pool using the default 'replicated_ruleset' rule:
cephadm@adm >ceph osd pool create cold-storage 100 100 replicated replicated_rulesetThen, setting up a cache tier involves associating a backing storage pool with a cache pool, in this case, cold storage (= storage pool) with hot storage (= cache pool):
cephadm@adm >ceph osd tier add cold-storage hot-storageTo set the cache mode to 'writeback', execute the following:
cephadm@adm >ceph osd tier cache-mode hot-storage writebackFor more information about cache modes, see Section 7.4, “Cache Modes”.
Writeback cache tiers overlay the backing storage tier, so they require one additional step: you must direct all client traffic from the storage pool to the cache pool. To direct client traffic directly to the cache pool, execute the following, for example:
cephadm@adm >ceph osd tier set-overlay cold-storage hot-storage
7.7 Configuring a Cache Tier #
There are several options you can use to configure cache tiers. Use the following syntax:
cephadm@adm > ceph osd pool set cachepool key value7.7.1 Hit Set #
Hit set parameters allow for tuning of cache pools. Hit sets in Ceph are usually bloom filters and provide a memory-efficient way of tracking objects that are already in the cache pool.
The hit set is a bit array that is used to store the result of a set of
hashing functions applied on object names. Initially, all bits are set to
0. When an object is added to the hit set, its name is
hashed and the result is mapped on different positions in the hit set,
where the value of the bit is then set to 1.
To find out whether an object exists in the cache, the object name is
hashed again. If any bit is 0, the object is definitely
not in the cache and needs to be retrieved from cold storage.
It is possible that the results of different objects are stored in the same
location of the hit set. By chance, all bits can be 1
without the object being in the cache. Therefore, hit sets working with a
bloom filter can only tell whether an object is definitely not in the cache
and needs to be retrieved from cold storage.
A cache pool can have more than one hit set tracking file access over time.
The setting hit_set_count defines how many hit sets are
being used, and hit_set_period defines for how long each
hit set has been used. After the period has expired, the next hit set is
used. If the number of hit sets is exhausted, the memory from the oldest
hit set is freed and a new hit set is created. The values of
hit_set_count and hit_set_period
multiplied by each other define the overall time frame in which access to
objects has been tracked.
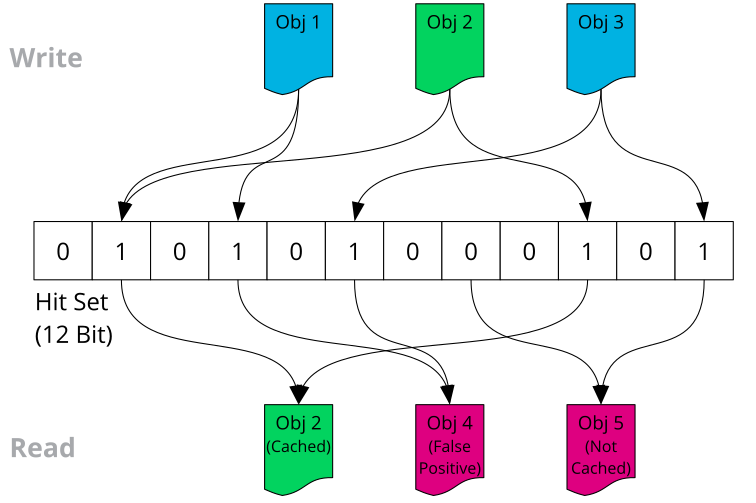
Figure 7.1: Bloom Filter with 3 Stored Objects #
Compared to the number of hashed objects, a hit set based on a bloom filter
is very memory-efficient. Less than 10 bits are required to reduce the
false positive probability below 1%. The false positive probability can be
defined with hit_set_fpp. Based on the number of objects
in a placement group and the false positive probability Ceph
automatically calculates the size of the hit set.
The required storage on the cache pool can be limited with
min_write_recency_for_promote and
min_read_recency_for_promote. If the value is set to
0, all objects are promoted to the cache pool as soon as
they are read or written and this persists until they are evicted. Any
value greater than 0 defines the number of hit sets
ordered by age that are searched for the object. If the object is found in
a hit set, it will be promoted to the cache pool. Keep in mind that backing
up objects may also cause them to be promoted to the cache. A full backup
with the value of '0' can cause all data to be promoted to the cache tier
while active data gets removed from the cache tier. Therefore, changing
this setting based on the backup strategy may be useful.
Note
The longer the period and the higher the
min_read_recency_for_promote and
min_write_recency_for_promote values, the more RAM the
ceph-osd daemon consumes. In
particular, when the agent is active to flush or evict cache objects, all
hit_set_count hit sets are loaded into RAM.
7.7.1.1 Use GMT for Hit Set #
Cache tier setups have a bloom filter called hit set. The filter tests whether an object belongs to a set of either hot or cold objects. The objects are added to the hit set using time stamps appended to their names.
If cluster machines are placed in different time zones and the time stamps are derived from the local time, objects in a hit set can have misleading names consisting of future or past time stamps. In the worst case, objects may not exist in the hit set at all.
To prevent this, the use_gmt_hitset defaults to '1' on a
newly created cache tier setups. This way, you force OSDs to use GMT
(Greenwich Mean Time) time stamps when creating the object names for the
hit set.
Warning: Leave the Default Value
Do not touch the default value '1' of use_gmt_hitset. If
errors related to this option are not caused by your cluster setup, never
change it manually. Otherwise, the cluster behavior may become
unpredictable.
7.7.2 Cache Sizing #
The cache tiering agent performs two main functions:
- Flushing
The agent identifies modified (dirty) objects and forwards them to the storage pool for long-term storage.
- Evicting
The agent identifies objects that have not been modified (clean) and evicts the least recently used among them from the cache.
7.7.2.1 Absolute Sizing #
The cache tiering agent can flush or evict objects based on the total number of bytes or the total number of objects. To specify a maximum number of bytes, execute the following:
cephadm@adm > ceph osd pool set cachepool target_max_bytes num_of_bytesTo specify the maximum number of objects, execute the following:
cephadm@adm > ceph osd pool set cachepool target_max_objects num_of_objectsNote
Ceph is not able to determine the size of a cache pool automatically, therefore configuration of the absolute size is required here. Otherwise, flush and evict will not work. If you specify both limits, the cache tiering agent will begin flushing or evicting when either threshold is triggered.
Note
All client requests will be blocked only when
target_max_bytes or target_max_objects
is reached.
7.7.2.2 Relative Sizing #
The cache tiering agent can flush or evict objects relative to the size of
the cache pool (specified by target_max_bytes or
target_max_objects in
Section 7.7.2.1, “Absolute Sizing”). When the cache pool
consists of a certain percentage of modified (dirty) objects, the cache
tiering agent will flush them to the storage pool. To set the
cache_target_dirty_ratio, execute the following:
cephadm@adm > ceph osd pool set cachepool cache_target_dirty_ratio 0.0...1.0For example, setting the value to 0.4 will begin flushing modified (dirty) objects when they reach 40% of the cache pool's capacity:
cephadm@adm > ceph osd pool set hot-storage cache_target_dirty_ratio 0.4
When the dirty objects reach a certain percentage of the capacity, flush
them at a higher speed. Use
cache_target_dirty_high_ratio:
cephadm@adm > ceph osd pool set cachepool cache_target_dirty_high_ratio 0.0..1.0
When the cache pool reaches a certain percentage of its capacity, the
cache tiering agent will evict objects to maintain free capacity. To set
the cache_target_full_ratio, execute the following:
cephadm@adm > ceph osd pool set cachepool cache_target_full_ratio 0.0..1.07.7.3 Cache Age #
You can specify the minimum age of a recently modified (dirty) object before the cache tiering agent flushes it to the backing storage pool. Note that this will only apply if the cache actually needs to flush/evict objects:
cephadm@adm > ceph osd pool set cachepool cache_min_flush_age num_of_secondsYou can specify the minimum age of an object before it will be evicted from the cache tier:
cephadm@adm > ceph osd pool set cachepool cache_min_evict_age num_of_seconds7.7.4 Examples #
7.7.4.1 Large Cache Pool and Small Memory #
If lots of storage and only a small amount of RAM is available, all objects can be promoted to the cache pool as soon as they are accessed. The hit set is kept small. The following is a set of example configuration values:
hit_set_count = 1 hit_set_period = 3600 hit_set_fpp = 0.05 min_write_recency_for_promote = 0 min_read_recency_for_promote = 0
7.7.4.2 Small Cache Pool and Large Memory #
If a small amount of storage but a comparably large amount of memory is available, the cache tier can be configured to promote a limited number of objects into the cache pool. Twelve hit sets, of which each is used over a period of 14,400 seconds, provide tracking for a total of 48 hours. If an object has been accessed in the last 8 hours, it is promoted to the cache pool. The set of example configuration values then is:
hit_set_count = 12 hit_set_period = 14400 hit_set_fpp = 0.01 min_write_recency_for_promote = 2 min_read_recency_for_promote = 2