2 Hardware Requirements and Recommendations #
The hardware requirements of Ceph are heavily dependent on the IO workload. The following hardware requirements and recommendations should be considered as a starting point for detailed planning.
In general, the recommendations given in this section are on a per-process basis. If several processes are located on the same machine, the CPU, RAM, disk and network requirements need to be added up.
2.1 Network Overview #
Ceph has several logical networks:
A trusted internal network, the back-end network called the the
cluster network.A public client network called
public network.Client networks for gateways, these are optional.
The trusted internal network is the back-end network between the OSD nodes for replication, re-balancing and recovery.Ideally, this network provides twice the bandwidth of the public network with default 3-way replication since the primary OSD sends 2 copies to other OSDs via this network. The public network is between clients and gateways on the one side to talk to monitors, managers, MDS nodes, OSD nodes. It is also used by monitors, managers, and MDS nodes to talk with OSD nodes.
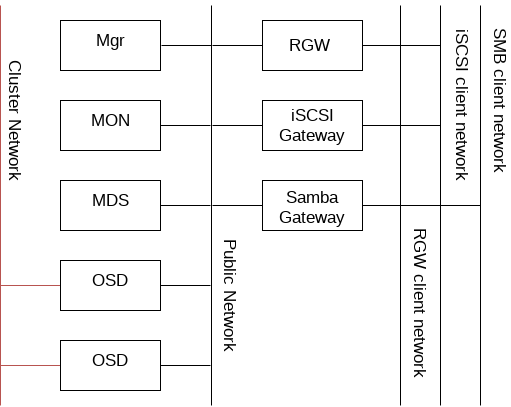
Figure 2.1: Network Overview #
2.1.1 Network Recommendations #
For the Ceph network environment, we recommend two bonded 25 GbE (or faster) network interfaces bonded using 802.3ad (LACP). The use of two network interfaces provides aggregation and fault-tolerance. The bond should then be used to provide two VLAN interfaces, one for the public network, and the second for the cluster network. Details on bonding the interfaces can be found in https://documentation.suse.com/sles/15-SP1/html/SLES-all/cha-network.html#sec-network-iface-bonding.
Fault tolerance can be enhanced through isolating the components into failure domains. To improve fault tolerance of the network, bonding one interface from two separate Network Interface Cards (NIC) offers protection against failure of a single NIC. Similarly, creating a bond across two switches protects against failure of a switch. We recommend consulting with the network equipment vendor in order to architect the level of fault tolerance required.
Important: Administration Network not Supported
Additional administration network setup—that enables for example separating SSH, Salt, or DNS networking—is neither tested nor supported.
Tip: Nodes Configured via DHCP
If your storage nodes are configured via DHCP, the default timeouts may
not be sufficient for the network to be configured correctly before the
various Ceph daemons start. If this happens, the Ceph MONs and OSDs
will not start correctly (running systemctl status
ceph\* will result in "unable to bind" errors). To avoid this
issue, we recommend increasing the DHCP client timeout to at least 30
seconds on each node in your storage cluster. This can be done by changing
the following settings on each node:
In /etc/sysconfig/network/dhcp, set
DHCLIENT_WAIT_AT_BOOT="30"
In /etc/sysconfig/network/config, set
WAIT_FOR_INTERFACES="60"
2.1.1.1 Adding a Private Network to a Running Cluster #
If you do not specify a cluster network during Ceph deployment, it assumes a single public network environment. While Ceph operates fine with a public network, its performance and security improves when you set a second private cluster network. To support two networks, each Ceph node needs to have at least two network cards.
You need to apply the following changes to each Ceph node. It is relatively quick to do for a small cluster, but can be very time consuming if you have a cluster consisting of hundreds or thousands of nodes.
Stop Ceph related services on each cluster node.
Add a line to
/etc/ceph/ceph.confto define the cluster network, for example:cluster network = 10.0.0.0/24
If you need to specifically assign static IP addresses or override
cluster networksettings, you can do so with the optionalcluster addr.Check that the private cluster network works as expected on the OS level.
Start Ceph related services on each cluster node.
root #systemctl start ceph.target
2.1.1.2 Monitor Nodes on Different Subnets #
If the monitor nodes are on multiple subnets, for example they are located
in different rooms and served by different switches, you need to adjust
the ceph.conf file accordingly. For example, if the
nodes have IP addresses 192.168.123.12, 1.2.3.4, and 242.12.33.12, add the
following lines to their global section:
[global] [...] mon host = 192.168.123.12, 1.2.3.4, 242.12.33.12 mon initial members = MON1, MON2, MON3 [...]
Additionally, if you need to specify a per-monitor public address or
network, you need to add a
[mon.X] section for each
monitor:
[mon.MON1] public network = 192.168.123.0/24 [mon.MON2] public network = 1.2.3.0/24 [mon.MON3] public network = 242.12.33.12/0
2.2 Multiple Architecture Configurations #
SUSE Enterprise Storage supports both x86 and Arm architectures. When considering each architecture, it is important to note that from a cores per OSD, frequency, and RAM perspective, there is no real difference between CPU architectures for sizing.
As with smaller x86 processors (non-server), lower-performance Arm-based cores may not provide an optimal experience, especially when used for erasure coded pools.
Note
Throughout the documentation, SYSTEM-ARCH is used in place of x86 or Arm.
2.3 Hardware Configuration #
For the best product experience, we recommend to start with the recommended cluster configuration. For a test cluster or a cluster with less performance requirements, we document a minimal supported cluster configuration.
2.3.1 Minimum Cluster Configuration #
A minimal product cluster configuration consists of:
At least four physical nodes (OSD nodes) with co-location of services
Dual-10 Gb Ethernet as a bonded network
A separate Admin Node (can be virtualized on an external node)
A detailed configuration is:
Separate Admin Node with 4 GB RAM, four cores, 1 TB storage capacity. This is typically the Salt master node. Ceph services and gateways, such as Ceph Monitor, Metadata Server, Ceph OSD, Object Gateway, or NFS Ganesha are not supported on the Admin Node as it needs to orchestrate the cluster update and upgrade processes independently.
At least four physical OSD nodes, with eight OSD disks each, see Section 2.4.1, “Minimum Requirements” for requirements.
The total capacity of the cluster should be sized so that even with one node unavailable, the total used capacity (including redundancy) does not exceed 80%.
Three Ceph Monitor instances. Monitors need to be run from SSD/NVMe storage, not HDDs, for latency reasons.
Monitors, Metadata Server, and gateways can be co-located on the OSD nodes, see Section 2.12, “OSD and Monitor Sharing One Server” for monitor co-location. If you co-locate services, the memory and CPU requirements need to be added up.
iSCSI Gateway, Object Gateway, and Metadata Server require at least incremental 4 GB RAM and four cores.
If you are using CephFS, S3/Swift, iSCSI, at least two instances of the respective roles (Metadata Server, Object Gateway, iSCSI) are required for redundancy and availability.
The nodes are to be dedicated to SUSE Enterprise Storage and must not be used for any other physical, containerized, or virtualized workload.
If any of the gateways (iSCSI, Object Gateway, NFS Ganesha, Metadata Server, ...) are deployed within VMs, these VMs must not be hosted on the physical machines serving other cluster roles. (This is unnecessary, as they are supported as collocated services.)
When deploying services as VMs on hypervisors outside the core physical cluster, failure domains must be respected to ensure redundancy.
For example, do not deploy multiple roles of the same type on the same hypervisor, such as multiple MONs or MDSs instances.
When deploying inside VMs, it is particularly crucial to ensure that the nodes have strong network connectivity and well working time synchronization.
The hypervisor nodes must be adequately sized to avoid interference by other workloads consuming CPU, RAM, network, and storage resources.

Figure 2.2: Minimum Cluster Configuration #
2.3.2 Recommended Production Cluster Configuration #
Once you grow your cluster, we recommend to relocate monitors, Metadata Server, and gateways on separate nodes to ensure better fault tolerance.
Seven Object Storage Nodes
No single node exceeds ~15% of total storage.
The total capacity of the cluster should be sized so that even with one node unavailable, the total used capacity (including redundancy) does not exceed 80%.
25 Gb Ethernet or better, bonded for internal cluster and external public network each.
56+ OSDs per storage cluster.
See Section 2.4.1, “Minimum Requirements” for further recommendation.
Dedicated physical infrastructure nodes.
Three Ceph Monitor nodes: 4 GB RAM, 4 core processor, RAID 1 SSDs for disk.
See Section 2.5, “Monitor Nodes” for further recommendation.
Object Gateway nodes: 32 GB RAM, 8 core processor, RAID 1 SSDs for disk.
See Section 2.6, “Object Gateway Nodes” for further recommendation.
iSCSI Gateway nodes: 16 GB RAM, 6-8 core processor, RAID 1 SSDs for disk.
See Section 2.9, “iSCSI Nodes” for further recommendation.
Metadata Server nodes (one active/one hot standby): 32 GB RAM, 8 core processor, RAID 1 SSDs for disk.
See Section 2.7, “Metadata Server Nodes” for further recommendation.
One SES Admin Node: 4 GB RAM, 4 core processor, RAID 1 SSDs for disk.
2.4 Object Storage Nodes #
2.4.1 Minimum Requirements #
The following CPU recommendations account for devices independent of usage by Ceph:
1x 2GHz CPU Thread per spinner.
2x 2GHz CPU Thread per SSD.
4x 2GHz CPU Thread per NVMe.
Separate 10 GbE networks (public/client and internal), required 4x 10 GbE, recommended 2x 25 GbE.
Total RAM required = number of OSDs x (1 GB +
osd_memory_target) + 16 GBThe default for
osd_memory_targetis 4 GB. Refer to Book “Administration Guide”, Chapter 25 “Ceph Cluster Configuration”, Section 25.2.1 “Automatic Cache Sizing” for more details onosd_memory_target.OSD disks in JBOD configurations or or individual RAID-0 configurations.
OSD journal can reside on OSD disk.
OSD disks should be exclusively used by SUSE Enterprise Storage.
Dedicated disk and SSD for the operating system, preferably in a RAID 1 configuration.
Allocate at least an additional 4 GB of RAM if this OSD host will host part of a cache pool used for cache tiering.
Ceph Monitors, gateway and Metadata Servers can reside on Object Storage Nodes.
For disk performance reasons, OSD nodes are bare metal nodes. No other workloads should run on an OSD node unless it is a minimal setup of Ceph Monitors and Ceph Managers.
SSDs for Journal with 6:1 ratio SSD journal to OSD.
2.4.2 Minimum Disk Size #
There are two types of disk space needed to run on OSD: the space for the disk journal (for FileStore) or WAL/DB device (for BlueStore), and the primary space for the stored data. The minimum (and default) value for the journal/WAL/DB is 6 GB. The minimum space for data is 5 GB, as partitions smaller than 5 GB are automatically assigned the weight of 0.
So although the minimum disk space for an OSD is 11 GB, we do not recommend a disk smaller than 20 GB, even for testing purposes.
2.4.3 Recommended Size for the BlueStore's WAL and DB Device #
We recommend reserving 4 GB for the WAL device. While the minimal DB size is 64 GB for RBD-only workloads, the recommended DB size for Object Gateway and CephFS workloads is 2% of the main device capacity (but at least 196 GB).
If you intend to put the WAL and DB device on the same disk, then we recommend using a single partition for both devices, rather than having a separate partition for each. This allows Ceph to use the DB device for the WAL operation as well. Management of the disk space is therefore more effective as Ceph uses the DB partition for the WAL only if there is a need for it. Another advantage is that the probability that the WAL partition gets full is very small, and when it is not used fully then its space is not wasted but used for DB operation.
To share the DB device with the WAL, do not specify the WAL device, and specify only the DB device.
Find more information about specifying an OSD layout in Section 5.5.2, “DriveGroups”.
2.4.4 Using SSD for OSD Journals #
Solid-state drives (SSD) have no moving parts. This reduces random access time and read latency while accelerating data throughput. Because their price per 1MB is significantly higher than the price of spinning hard disks, SSDs are only suitable for smaller storage.
OSDs may see a significant performance improvement by storing their journal on an SSD and the object data on a separate hard disk.
Tip: Sharing an SSD for Multiple Journals
As journal data occupies relatively little space, you can mount several journal directories to a single SSD disk. Keep in mind that with each shared journal, the performance of the SSD disk degrades. We do not recommend sharing more than six journals on the same SSD disk and 12 on NVMe disks.
2.4.5 Maximum Recommended Number of Disks #
You can have as many disks in one server as it allows. There are a few things to consider when planning the number of disks per server:
Network bandwidth. The more disks you have in a server, the more data must be transferred via the network card(s) for the disk write operations.
Memory. RAM above 2 GB is used for the BlueStore cache. With the default
osd_memory_targetof 4 GB, the system has a reasonable starting cache size for spinning media. If using SSD or NVME, consider increasing the cache size and RAM allocation per OSD to maximize performance.Fault tolerance. If the complete server fails, the more disks it has, the more OSDs the cluster temporarily loses. Moreover, to keep the replication rules running, you need to copy all the data from the failed server among the other nodes in the cluster.
2.5 Monitor Nodes #
At least three Ceph Monitor nodes are required. The number of monitors should always be odd (1+2n).
At least 4 GB of RAM. For large clusters, provide 5-10 GB of RAM.
Processor with four logical cores.
An SSD or other sufficiently fast storage type is highly recommended for monitors, specifically for the
/var/lib/cephpath on each monitor node, as quorum may be unstable with high disk latencies. Two disks in RAID 1 configuration is recommended for redundancy. It is recommended that separate disks or at least separate disk partitions are used for the monitor processes to protect the monitor's available disk space from things like log file creep.There must only be one monitor process per node.
Mixing OSD, monitor, or Object Gateway nodes is only supported if sufficient hardware resources are available. That means that the requirements for all services need to be added up.
Two network interfaces bonded to multiple switches.
2.6 Object Gateway Nodes #
Object Gateway nodes should have six to eight CPU cores and 32 GB of RAM (64 GB recommended). When other processes are co-located on the same machine, their requirements need to be added up.
2.7 Metadata Server Nodes #
Proper sizing of the Metadata Server nodes depends on the specific use case. Generally, the more open files the Metadata Server is to handle, the more CPU and RAM it needs. The following are the minimum requirements:
3 GB of RAM for each Metadata Server daemon.
Bonded network interface.
2.5 GHz CPU with at least 2 cores.
2.8 Admin Node #
At least 4 GB of RAM and a quad-core CPU are required. This includes running the Salt master on the Admin Node. For large clusters with hundreds of nodes, 6 GB of RAM is suggested.
2.9 iSCSI Nodes #
iSCSI nodes should have six to eight CPU cores and 16 GB of RAM.
2.10 SUSE Enterprise Storage 6 and Other SUSE Products #
This section contains important information about integrating SUSE Enterprise Storage 6 with other SUSE products.
2.10.1 SUSE Manager #
SUSE Manager and SUSE Enterprise Storage are not integrated, therefore SUSE Manager cannot currently manage a SUSE Enterprise Storage cluster.
2.11 Naming Limitations #
Ceph does not generally support non-ASCII characters in configuration files, pool names, user names and so forth. When configuring a Ceph cluster we recommend using only simple alphanumeric characters (A-Z, a-z, 0-9) and minimal punctuation ('.', '-', '_') in all Ceph object/configuration names.
2.12 OSD and Monitor Sharing One Server #
Although it is technically possible to run Ceph OSDs and Monitors on the same server in test environments, we strongly recommend having a separate server for each monitor node in production. The main reason is performance—the more OSDs the cluster has, the more I/O operations the monitor nodes need to perform. And when one server is shared between a monitor node and OSD(s), the OSD I/O operations are a limiting factor for the monitor node.
Another consideration is whether to share disks between an OSD, a monitor node, and the operating system on the server. The answer is simple: if possible, dedicate a separate disk to OSD, and a separate server to a monitor node.
Although Ceph supports directory-based OSDs, an OSD should always have a dedicated disk other than the operating system one.
Tip
If it is really necessary to run OSD and monitor node
on the same server, run the monitor on a separate disk by mounting the disk
to the /var/lib/ceph/mon directory for slightly better
performance.